188金宝博(188BET) LLM近期要紧架构进化一览: 从Gemma 4到DeepSeek V4


机器之心剪辑部
当年一段时辰,许多东谈主对大模子都有一个彰着感受:token 老是不够用。
毕竟用户想大模子更「贤达」更连贯,潦倒文窗口只会越来越大。
而在模子背后,长潦倒文吵嘴常「虚耗」的。用户 token 破钞翻倍,其实是模子更大的 KV cache 和更高的 attention 诡计资本。
尤其是在推理模子和 Agent 拖拉成为主流后,长潦倒文依然从一个「宣传亮点」,拖拉鼎新为大模子架构设想需要正面禁止的问题。
Sebastian 精确地捕捉到,最近几个月发布的一批 LLM,偶合体现了这个趋势。
从 Google 的 Gemma 4,到 Poolside 的 Laguna XS.2、Zyphra 的 ZAYA1-8B,再到 DeepSeek V4,这些模子在 Transformer 里面作念了多样「省钱设想」,试图围绕长潦倒文推理裁汰诡计和存储资本。
Sebastian 为此发布了时期博客,以下为博客鸠合与全文翻译。
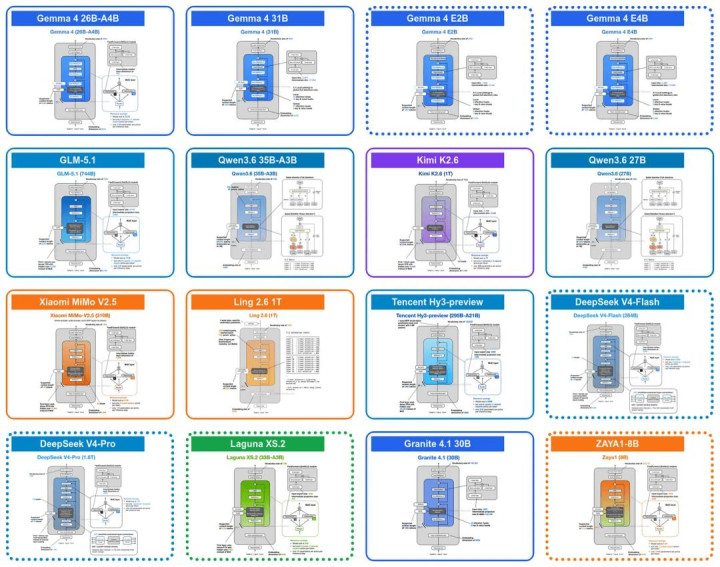
近期 LLM 一览。
博客标题:LLM 架构的最新发展:KV 分享、mHC 与压缩注重力
博客鸠合:https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
Gemma 4:
通过跨层复用 KV Tensor 缩小 KV Cache
时辰回到四月初,Google 发布了全新的开源权重模子系列 Gemma 4。通盘系列大致不错分为三类:
面向转移端与袖珍土产货(镶嵌式)开拓(即 IoT)的 Gemma 4 E2B 与 E4B;
面向高效土产货推理、罗致搀和众人架构(MoE)的 Gemma 4 26B;
以及罗致 Dense 架构、追求更高模子质料与更方便后磨真金不怕火进程的 Gemma 4 31B(因为 MoE 模子频繁更难进行后磨真金不怕火和调优)。
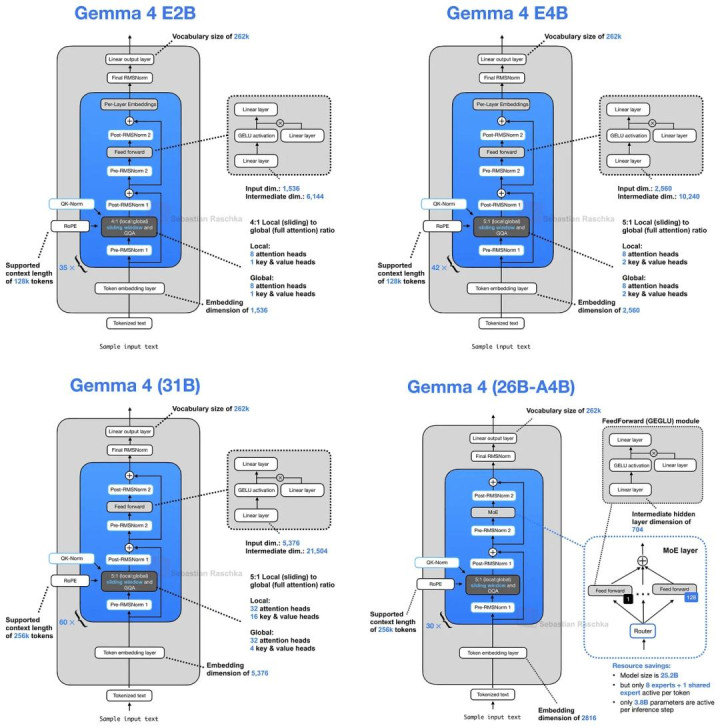
Gemma 4 架构示意图
Gemma 4 E2B 与 E4B 的第一个袖珍架构调动,是罗致了「分享 KV Cache」机制:后续层会复用前边层依然诡计出的 Key-Value 气象,从而裁汰长潦倒文场景下的显存占用与诡计资本。
这种设施并不是 Gemma 4 开创。举例 NeurIPS 2024 的论文《Reducing Transformer Key-Value Cache Size with Cross-Layer Attention》依然建议雷同念念路。但 Gemma 4 是第一次将其大范畴运用于主流开源架构中。
为什么 KV Cache 如斯热切?
正如我最近几个月延续提到的,现时 LLM 架构设想中的一个中枢主题,等于「缩小 KV Cache」。而缩小 KV Cache 的根柢办法,是裁汰模子运行所需的显存占用,从而复旧更长的潦倒文窗口。这一丝在推理模子和 Agent 时间尤其热切。
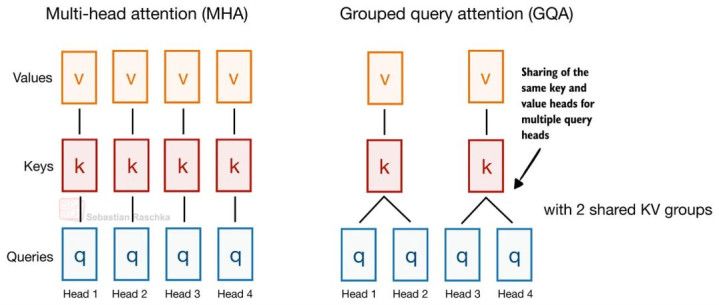
举一个经典的例子(Gemma 4 当今依然在使用):Grouped Query Attention(GQA)自己就依然通过让多个 Query Head 分享归拢组 Key-Value(KV)Head,来减少 KV Cache 的大小,如下图所示。
Gemma 4 的跨层 KV 分享机制
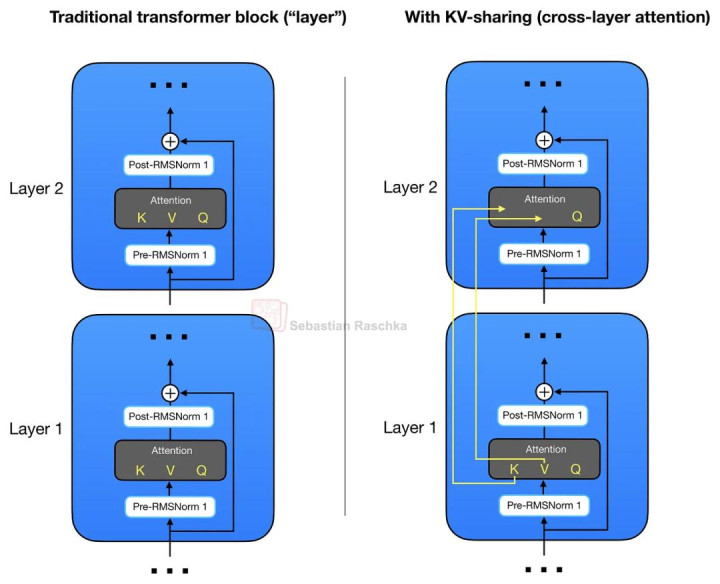
如前所述,Gemma 4 使用了 GQA。不外,除了 GQA 中不同 Query Head 之间的 KV 分享以外,Gemma 4 还进一步在不同 Transformer Layer 之间分享 KV Projection,而不是像传统作念法那样,在每一层 Attention 模块平分离诡计我方的 KV。
这种 KV 分享机制也被称为 Cross-Layer Attention,其结构如下图所示。
正如架构示意图中所提到的,Gemma 4 E2B 罗致了普通 GQA 与 Sliding Window Attention 按照 4:1 的方式组合使用。(更准确地说,Gemma 4 E2B 本质使用的是 MQA,也等于 GQA 中唯唯独个 KV Head 的特殊情况。)
在 GQA(或 MQA)机制下,KV 分享的方式如下:后续层不再单独诡计我方的 Key 和 Value Projection,而是径直复用最近一个、同类型且未分享层所生成的 KV Tensor。
换句话说:Sliding Window Attention 层会复用前边某个 Sliding Window 层的 KV, Full Attention 层则会复用前边某个 Full Attention 层的 KV。
天然,每一层仍然司帐算我方的 Query Projection,因此不同层依然不错变成各自不同的 Attention Pattern;但代价最高、最占显存的 KV Cache,则会被多个层共同复用。举例:
Gemma 4 E2B 一共有 35 层 Transformer Layer,但唯独前 15 层会着实诡计我方的 KV Projection;后头的 20 层则径直复用之前同类型层的 KV Tensor。
雷同地,Gemma 4 E4B 共 42 层,其中 24 层负责诡计 KV,终末 18 层罗致分享机制。
这种设想到底能省俭若干资源?
由于大要有一半的 KV 在不同层之间被分享,因此 KV Cache 的举座大小也大致减少了一半。对于最小的 E2B 模子来说,在 128K 长潦倒文、bfloat16 精度下,不错省俭约 2.7GB 显存;而 E4B 在一样要求下,则大要概况省俭 6GB。
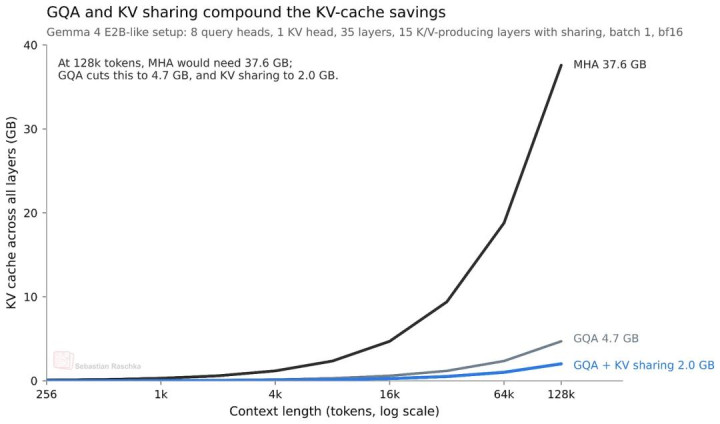
Gemma 4 E2B 雷同成就中,GQA 与跨层 KV 分享带来的 KV Cache 显存省俭恶果
天然,KV Sharing 的污点在于,它骨子上是一种对好意思满 Attention 诡计的「近似」。更准确地说,它会平缓模子容量。
不外,凭证 Cross-Layer Attention 论文中的实验末端,在被测试的小范畴模子上,这种影响不错相称有限。
Gemma 4 E2B / E4B:
Per-Layer Embeddings(PLE)与「灵验参数目」
Gemma 4 的 E2B 与 E4B 版块还引入了第二种以着力为导向的设想:Per-Layer Embeddings(PLE,逐层镶嵌)。这一机制与前边提到的 KV Sharing 是互相落寞的。
KV Sharing 的方向是缩小 KV Cache,而 PLE 温暖的则是参数着力(parameter efficiency):它让小尺寸的 Gemma 4 模子概况佩带更多 token-specific information(与 token 相干的特征信息),但又不会让通盘 Transformer 骨干像同参数目 Dense 模子那样腾贵。
举例,Gemma 4 E2B 与 E4B 中的「E」,代表的等于「effective」(灵验参数目) 。具体来说:
Gemma 4 E2B 标注为 2.3B effective parameters,但如果把 embedding 参数也算进去,总参数目本质上达到 5.1B;
Gemma 4 E4B 的 effective parameters 为 4.5B,而包含 embedding 后则约为 8B。
换句话说,在这些 「E」系列模子中,着实负责主要诡计的 Transformer Stack,其诡计范畴更接近前边的较极少字;此后头的总参数目,则包含了异常的 embedding table。
从成见上来看,PLE 的结构大致如下:
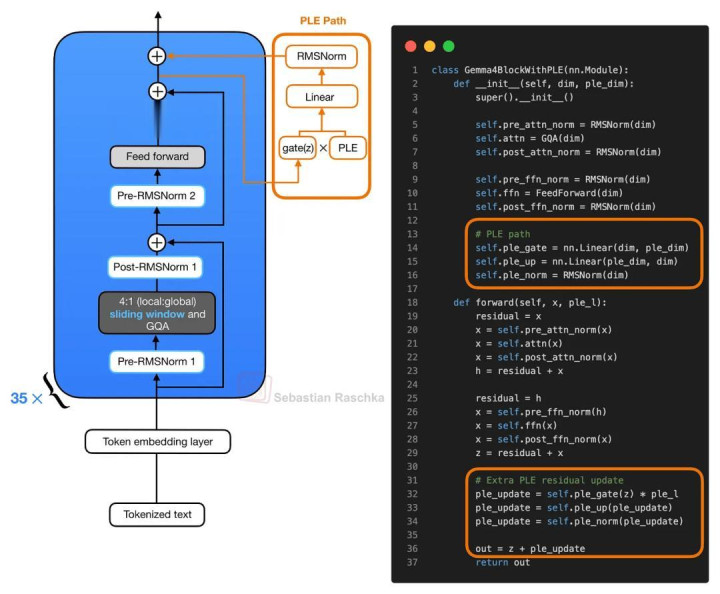
带有 PLE residual path 的简化版 Gemma 4 Block。普通 Transformer Block 会先完成 Attention 与 Feed-Forward 的 residual update;随后,生成的 hidden state 会作为 gating 信号,截止 layer-specific 的 PLE vector,并在 Block 末尾异常加入一次 projected PLE residual update。
PLE Vector 自己是在 Transformer Block 外部提前构建的。节略来说,它有两个输入来源:token ID 经过 per-layer embedding lookup; 普通 token embedding 再通过一个 linear projection,映射到归拢个 PLE 空间。
随后,这两部分末端会被相加、缩放,并 reshape 成一个 tensor,其中每一层都对应一个落寞 slice,而每个 Transformer Block 只会经受属于我方的那一份。
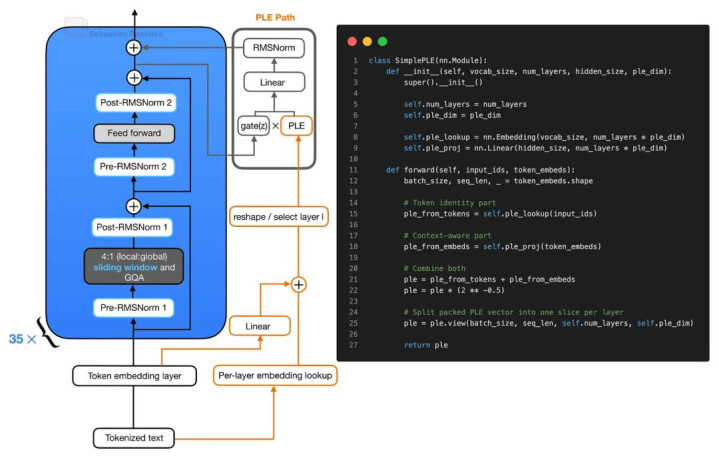
简化版 PLE(Per-Layer Embeddings)构建进程
这里有一个很热切的细节:PLE 并不是给每个 Transformer Block 单独复制一整套 embedding layer。相背,per-layer embedding lookup 只司帐算一次,然后再给每一层分发一个较小的 token-specific embedding slice。
因此,对于每个输入 token,Gemma 4 会提前准备一个 packed PLE tensor,其中包含每一层 decoder 对应的一小段 embedding vector。
着实进入 Transformer Block 后,Attention 与 Feed-Forward 分支仍然按正常方式运行。在完成 Feed-Forward residual update 后,现时 hidden state(图中记作 z)会用于 gate layer-specific PLE vector。被 gate 后的 PLE vector 会重新投影回 model hidden size、作念 normalization,并作为异常 residual update 加回模子中。
一个比较直不雅的和会方式是 Transformer Block 的主体结构并莫得改变,Gemma 4 只是异常皮 Feed-Forward 分支后头,插入了一小段「层特定 token 向量」。这么作念概况通过 embedding 参数与小范畴 projection,擢升模子的抒发才智,同期幸免把通盘 Transformer Stack 都膨大到更大的参数范畴。
为什么要用 PLE?
一种更径直的设施,其实是节略缩小 Dense 模子,比如减少层数、缩小 hidden state 或缩小 Feed-Forward Network。
这么天然能裁汰显存与延伸,但也会径直平缓模子着实负责诡计的中枢部分。
而 PLE 的念念路则是:让腾贵的 Transformer Block 保合手在较小的 「effective size」,同期把异常容量存储在 per-layer embedding table 中。由于 embedding 骨子上主如若 lookup-style parameter,它们远比增多 Attention 或 FFN 权重更低廉,也更容易缓存。
天然,当今咱们还只可驯服 Google 的实验末端,以为这确乎是一个灵验的设想。作家也提到,将来如果能看到更多对比实验,举例:PLE 版 Gemma 4 E2B vs 普通 2.3B Dense 模子 vs 普通 5.1B Dense 模子 。
这么的对比会相称特好奇。
此外,从表面上讲,2026美加墨世界杯中国认证平台PLE 并不单适用于小模子。更大的模子一样不错加入 per-layer embedding slice。但由于大模子自己依然具有阔绰容量,因此这些异常 embedding 的收益可能不再彰着。而且在大模子中,咱们频繁依然通过 MoE 等结构,在不显耀增多诡计量的前提下擢升模子容量。
Laguna XS.2:
Layer-wise Attention Budgeting
Laguna 是欧洲公司 Poolside 推出的首个 open-weight 模子,Poolside 主要专注于面向代码场景的 LLM 磨真金不怕火。
不同 Layer 使用不同 Attention Budget。
下图中的 Laguna XS.2 架构乍一看其实非常法式。不外,有一个我莫得画进去(或者说没法硬塞进图里)的细节,是一个不错称为 「Layer-wise attention budgeting」 的成见。
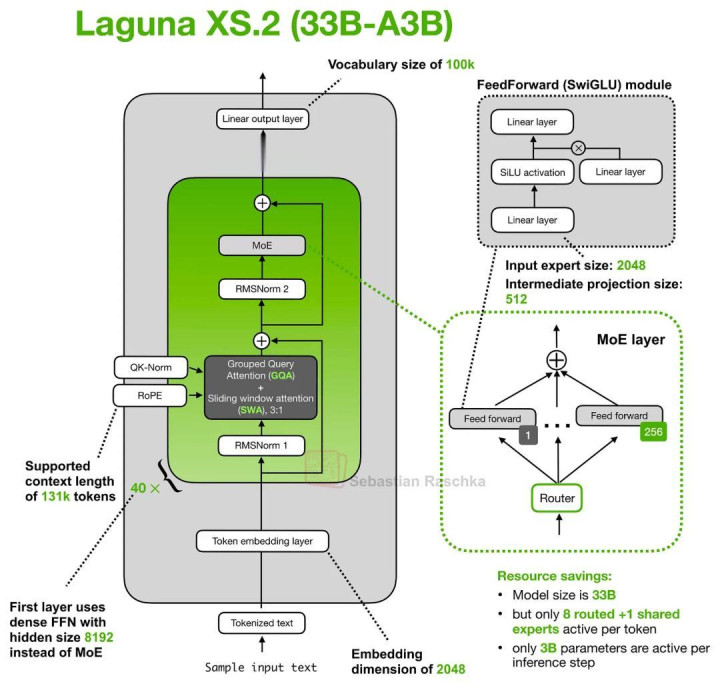
Poolside 的 Laguna XS.2 架构示意图。
这里所谓 attention budgeting 的中枢念念路之一,是不再让每个 Transformer Layer 都领有完全相易的 Attention 预算,而是凭证层的不同,动态分派不同的 Attention 资本。
Laguna XS.2 统统有 40 层,其中 30 层使用 Sliding-Window Attention,10 层使用 Global / Full Attention。
和常见作念法一样,Sliding-Window Layer 只会温暖局部窗口(这里是 512 个 token),因此 KV Cache 与 Attention 诡计资本都更低;而 Global Layer 天然更腾贵,但概况保留对通盘潦倒文窗口中系数信息的拜访才智。
这种 Sliding-Window Attention 与 Global / Full Attention 搀和使用的结构,并不是 Laguna XS.2 特有的,许多其他模子(包括 Gemma 4)也罗致了雷同设想。
但着实新的场所在于:Laguna XS.2 引入了「逐层不同 Query Head 数目」的设想。
举例,在 Hugging Face 的 config.json 中,不错看到一个名为 num_attention_heads_per_layer 的成就项,这意味着不同 Layer 不错领有不同数目的 Query Head,同期仍然保合手 KV Cache 结构兼容。
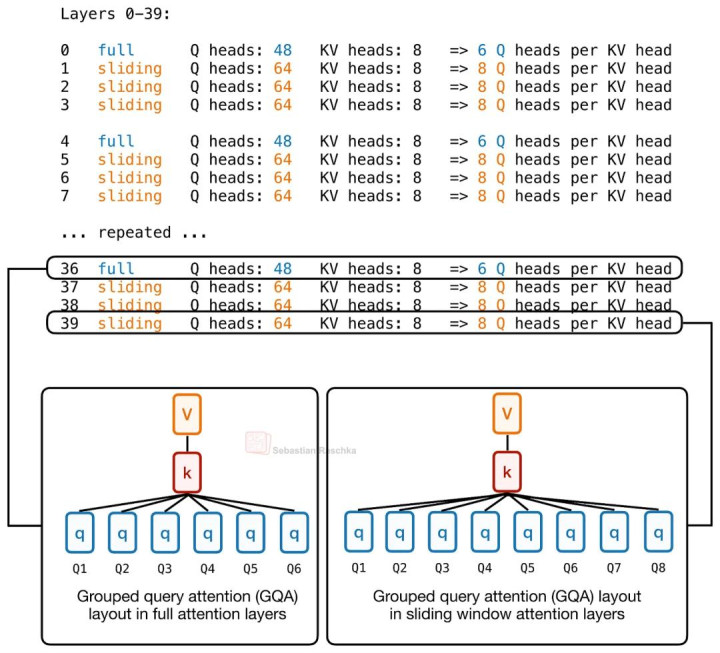
Laguna 中的逐层 Query-Head Budgeting。其中 Full Attention Layer 每个 KV Head 对应 6 个 Query Head; Sliding Window Attention Layer 每个 KV Head 对应 8 个 Query Head。
因此,Laguna XS.2 的本质作念法是:给 Sliding-Window Layer 分派更多 Query Head,给 Global Layer 分派更少 Query Head,同期将 KV Head 数固定为 8。
这才是着实道理上的 「Layer-wise Head Budgeting」。
Laguna XS.2 是近期 open model 中最具代表性的逐层 Query-Head Budgeting 实践之一。不外,更广义上的「按层动态分派模子容量」这一念念路,其实至少不错回首到 Apple 在 2024 年建议的 OpenELM。
为什么这么设想?
和 KV Sharing 雷同,它的中枢方向依然是:把 Attention Capacity 花在最值得的场所,而不是让系数 Layer 平均分派相易预算。
具体来说,Full Attention Layer 因为需要拜访通盘潦倒文窗口,自己诡计代价就更高,因此 Laguna 会相对减少它们的 Query Head 数目;而诡计资本更低的 Sliding-Window Layer,则不错领有更多 Query Head。
(此外,还有一个较小的终了细节:Laguna 还罗致了 per-head attention-output gating,这一丝与 Qwen3-Next 等模子有些雷同。不外由于我之前依然商榷过雷同机制,因此这里不再张开。)
ZAYA1-8B:压缩卷积注重力(CCA)
和 Laguna 雷同,ZAYA1-8B 亦然一位新玩家。它由 Zyphra 开发,而此次发布中一个很特好奇的细节是:该模子并不是基于更常见的 NVIDIA GPU(或 Google TPU)磨真金不怕火,而是使用 AMD GPU 完成磨真金不怕火的。
不外,着实要津的架构设想,是一种名为 Compressed Convolutional Attention(CCA,压缩卷积注重力)的机制,而况它与 Grouped-Query Attention(GQA)共同使用。
与 MLA(Multi-head Latent Attention)这类主要把 latent representation 行动紧凑 KV Cache 方式的设想不同,CCA 会径直在压缩后的 latent space 中完成 Attention 诡计。不外这一丝咱们后头再详备张开。
(顺带一提:ZAYA1-8B 的 config.json 中本质上列出了 80 个轮换出现的 layer entry,而不是传统道理上的 40 个 Transformer Block。这些 layer 在结构上会在 CCA/GQA Attention 与 MoE Feed-Forward Layer 之间轮换出现。不外在架构图里,把它们简化和会成 40 个叠加的 「Attention + MoE」 Pair 会更直不雅,两种透露在成见上是等价的。)
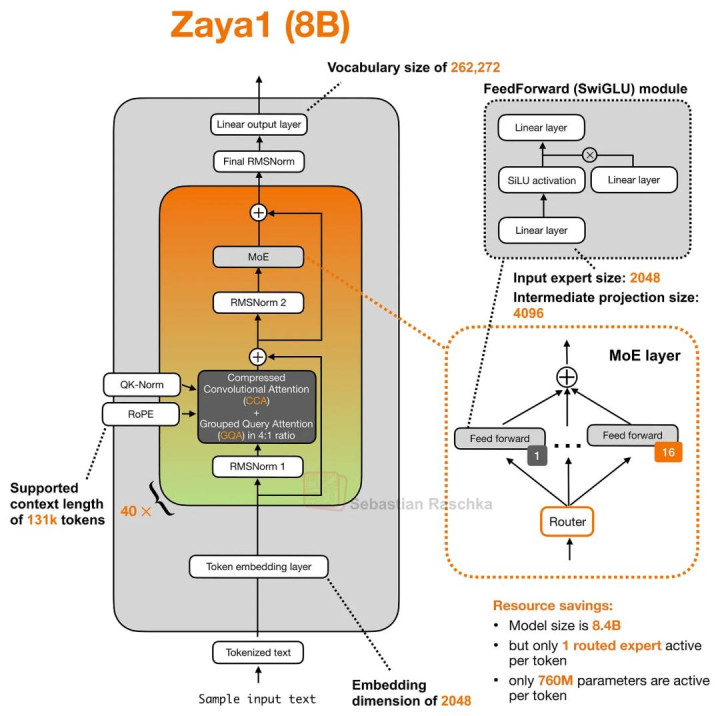
罗致 Compressed Convolutional Attention 的 ZAYA1(8B)Transformer Block。
正如上图所示,ZAYA1-8B 罗致了 CCA,并结合了 4:1 的 GQA 结构。这里最要津的一丝在于:它的 Attention Block 是围绕 CCA 构建的,而不是传统的 Sliding-Window Attention。
什么是 Compressed Convolutional Attention(CCA)?
我以为,188金宝博官网app下载从举座念念路上来看,CCA 与 DeepSeek 模子中的 MLA(Multi-head Latent Attention)是周边的,因为它们都在 Attention Block 中引入了压缩后的 latent representation。不外,两者使用 latent space 的方式并不相易。
MLA 的中枢方向,主如若通过 latent representation 来压缩 KV Cache。在 MLA 中,KV Tensor 会以压缩神情存储,随后再被投影回 Attention Head 空间,用于着实的 Attention 诡计。
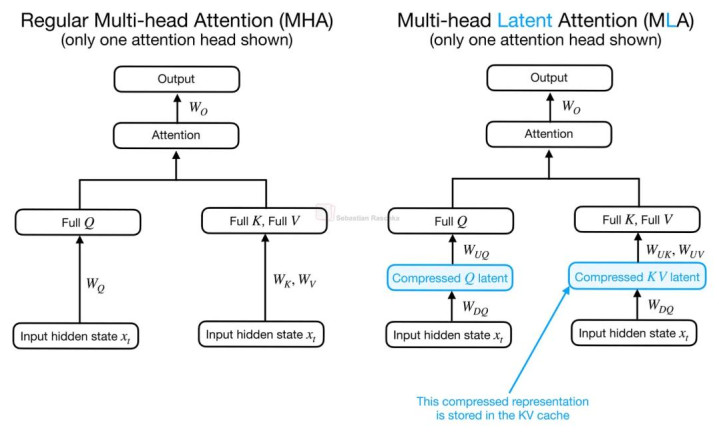
普通 Multi-head Attention(MHA)与 Multi-head Latent Attention(MLA)对比。
而 CCA 则更进一步,它不仅压缩 K、V,还同期压缩 Q,而况径直在压缩后的 latent space 中完成 Attention 运算。也正因为如斯,CCA 不仅概况减少 KV Cache 的大小,还概况裁汰 Prefill 阶段与磨真金不怕火阶段的 Attention FLOPs。
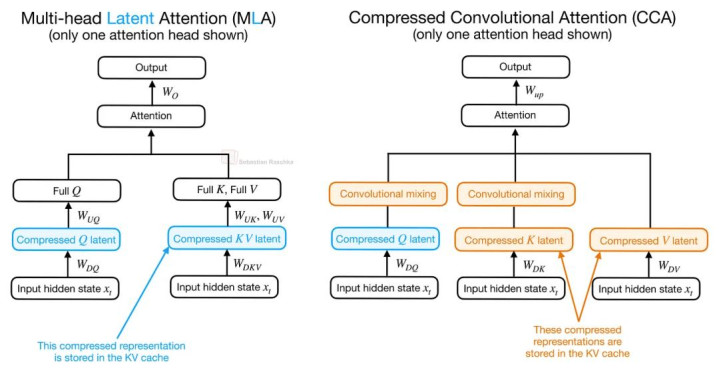
MLA 与 CCA 的结构对比。
正如上图所示的,在 CCA 中,压缩后的 latent representation 会径直进入 Attention 机制,而生成出的 compressed attention vector 随后再被 up-project 回原始空间。
为什么叫「卷积注重力」?
这里需要特殊注重:它被称为 「Compressed Convolutional Attention」,而不单是是「Compressed Attention」,是因为在 latent K 与 latent Q 上,还异常加入了 convolutional mixing(卷积搀和)。
由于结构图中空间有限,莫得把这一部分画出来,但它自己其实并不复杂。正如 Figure 12 所暗意的,卷积搀和是径直作用在压缩后的 Q Tensor 与 K Tensor 上的。
原因在于压缩会让 Q、K、V 维度变窄,从而裁汰诡计量与缓存支拨,但与此同期,也可能平缓 Attention 的抒发才智。
而卷积则是一种相对低价的设施,它概况在 Q 与 K 被用于 Attention Score 诡计之前,为这些压缩后的透露补充更多局部潦倒文信息。
(这里的卷积只作用于 Q 与 K,而不作用于 V。因为 Q 与 K 决定的是 Attention Score,而 V 则代表最终被加权团聚的内容。)
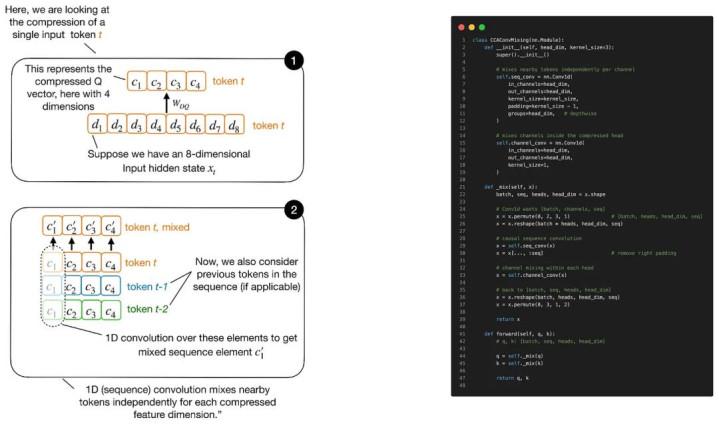
Sequence-Mixing Convolution 的成见示意图。
除了前文中展示的 Sequence Mixing 外,CCA 还包含一个 Channel Mixing Component。不外它们在道理上较为雷同,因此这里不再单独张开。
CCA 看起来是 Zyphra 在 ZAYA1-8B Technical Report 发布之前就依然建议的一种 Attention 机制。落寞论文《Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space》最早发表于 2025 年 10 月,并认真建议了 CCA;而 ZAYA1-8B 则将这一机制作为中枢架构组件之一本质插足使用。
CCA 是否确凿比 MLA 更好?
凭证 CCA 论文中的实验末端,在相易压缩缔造下,CCA 的发达确乎优于 MLA。
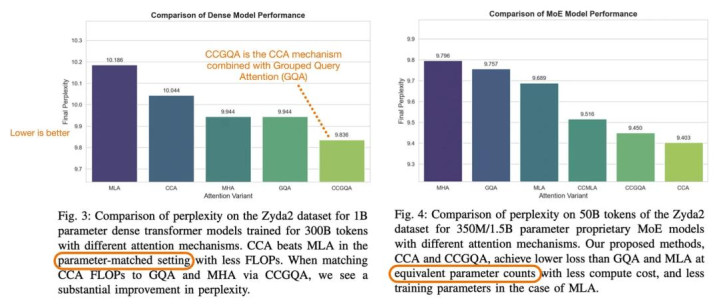
CCA 论文中的实验末端标注图。
总体来说,这部分着实特好奇的场所,其实是新的 Attention 机制自己。
天然,ZAYA1-8B 同期也罗致了非常激进(也就黑白常阑珊)的 MoE 结构:每个 token 只激活一个 routed expert。不外这一丝相对依然比较常见。
着实更特殊的是 CCA,它径直在压缩 latent space 中实施 Attention 诡计,并通过对压缩后的 Q/K 作念卷积搀和,来缓解压缩 Attention 自己抒发才智受限的问题。
简而言之,ZAYA1-8B 不单是想在 Feed-Forward Layer 上省俭诡计量,它致使试图从 Attention Mechanism 自己运转裁汰诡计资本。
DeepSeek V4:mHC 与压缩注重力
DeepSeek V4 是本年最受温暖的大模子之一。特好奇的是,如果按照 active-parameter share(活跃参数占比)来估量,DeepSeek V4-Pro 同期亦然参数最阑珊的 MoE 模子。
对于 DeepSeek V4,其实有许多不错商榷的内容。不外由于它依然在新闻与社区中被深切商榷,同期为了连接聚焦「架构层面的调动」,这里我主要温暖两个相较以往架构着实新的部分:
用于膨大 Residual Path 的 mHC;
用于长潦倒文 Attention 压缩与阑珊化的 CSA/HCA。
从下图中的 DeepSeek V4 架构图来看,通盘结构似乎相称复杂。不外,一个比较灵验的阅读方式是将 Residual Path 上的调动(mHC),与 Attention Path 上的调动(CSA/HCA 与 Compressed Attention Cache)分开和会。
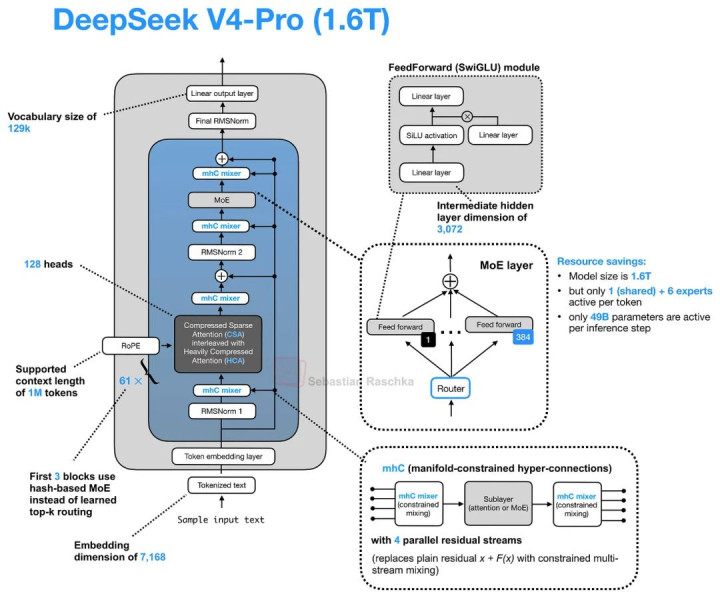
DeepSeek V4-Pro 架构概览。
5.1 mHC:流形禁止超迷惑
咱们先从 DeepSeek V4 中的 mHC 组件运转。
这一设想最早来自 DeepSeek 团队在前年(2025 年 12 月 31 日)发布的一篇连系论文《mHC: Manifold-Constrained Hyper-Connections》。不外,其时论文中的实验只在一个 27B 范畴的实验模子上完成。而如今,咱们依然在他们的旗舰模子中看到了这一机制,这也意味着,这一想法很可能依然在着实分娩环境中被考据灵验。
mHC 的中枢方向,是重新设想 Transformer Block 里面的 Residual Connection。这一丝其实相称簇新,因为连年来绝大多数架构调动,频繁都聚拢在Attention Mechanism、Normalization Layer 的摈弃方式与MoE 结构自己。
mHC 自己开拓在更早的 Hyper-Connections 使命之上(见 Zhu 等东谈主 2024 年论文《Hyper-connections》),因此咱们需要先节略和会一下 Hyper-Connections。
传统 Transformer 中,唯唯独条单独的 Residual Stream。而 Hyper-Connections 会把它替换成:多条并行 Residual Stream,并通过可学习映射(learned mappings)在它们之间交换信息。
Hyper-Connections 的中枢念念想,是「扩宽 Residual Stream」。
不错把它和会为模子同期贵重多条并行 Residual Path,并异常加入一个 Res Mapping 线性变换,在不同 Residual Stream 之间进行信息搀和。
由于 Attention Layer 或 MoE Layer 自己仍然使命在普通 Hidden Size 上,因此 Hyper-Connections 还会增多:
Pre Mapping:把多条 Residual Stream 合并成单一 Hidden Vector;
Post Mapping:再把 Layer 输出重新分发还多个 Residual Stream。
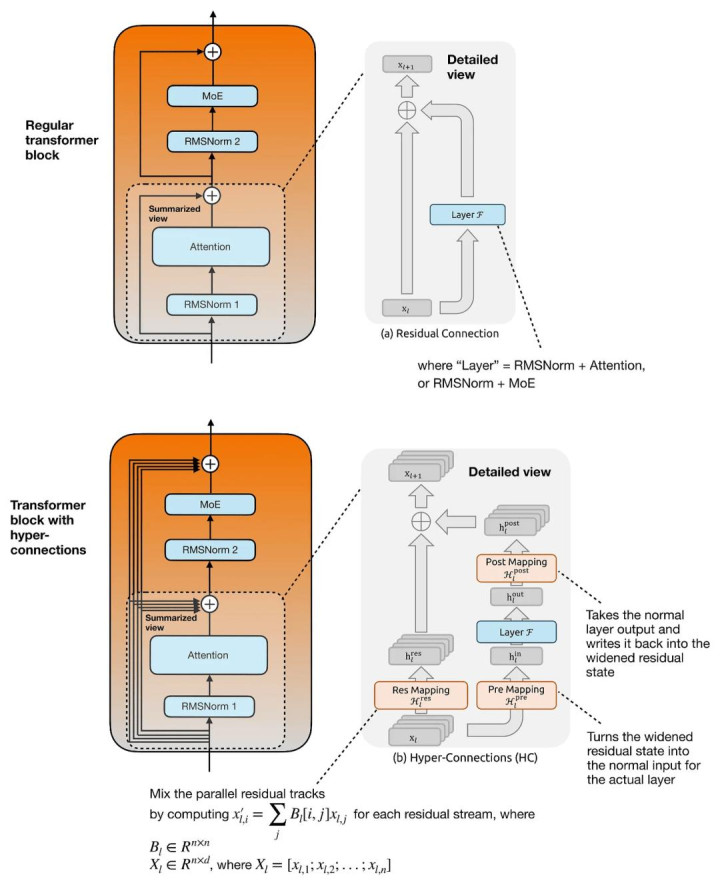
普通 Transformer Block(上)与带 Hyper-Connections 的 Transformer Block(下)。
上图主要展示了 Attention Branch 中的结构,但一样的念念想也适用于围绕 MoE Layer 的第二条 Residual Branch。
Hyper-Connections 的办法,是在不着实扩大 Attention 或 MoE Layer 自己宽度的情况下,让 Residual Path 领有更强抒发才智。
而它带来的 FLOPs 增长其实很有限,因为这些异常映射只作用在较小的 residual-stream 维度上(举例 DeepSeek V4 中 n=4),而不是作用在强大的 hidden dimension 上。
在来源的 Hyper-Connections 论文中,7B OLMo MoE 模子的 FLOPs per token 从 13.36G 增多到 13.38G,险些莫得变化;而性能筹谋则赢得了通晓但谦让的擢升。
天然,只看 FLOPs 其实有些过于节略。因为扩宽后的 Residual State 依然需要存储、在显存中转移并参与混总诡计。 因此,着实的异常支拨更多可能来自Memory Traffic 与 Implementation Complexity,而不单是是算术诡计自己。
不外斟酌到 DeepSeek V4 举座都在追求着力,这看起来依然是一个值得加入的设想。

Hyper-Connections 相较 Baseline 的性能发达。
传统 Transformer 唯独单一 residual stream。而 Hyper-Connections 将其膨大成多个并行 residual stream。
此外,如图所示:Hyper-Connections 在大要只使用一半磨真金不怕火 token 的情况下,就达到了 Baseline 的性能水平。
而从普通 Hyper-Connections(HC)到 Manifold-Constrained Hyper-Connections(mHC)最要津的变化,在于这些 Mapping 不再是「无禁止」的。
在普通 HC 中,Res Mapping 是一个可学习矩阵,用于搀和不同 Residual Stream。但当多个这么的矩阵延续堆叠时,信号可能会不能预计地被放大或缩小。
而在 mHC 中,这个 Residual Mapping 会被禁止到「双立时矩阵(doubly stochastic matrix)」流形上。也等于说:系数元素非负; 每一排之和为 1; 每一列之和为 1。
这么一来:Residual Mixing 会更像是一种通晓的信息重新分派(stable redistribution),而不是不能控的信号放大或衰减。
与此同期 Pre Mapping 与 Post Mapping 也一样会被禁止为非负且有界,从而幸免在读取与写回扩宽 Residual State 时出现信息对消。
简而言之,mHC 保留了 HC 更丰富的 Residual Mixing 才智,同期加入异常禁止,使其在更大、更深的模子中概况更通晓地膨大。
除此以外,多 Residual Stream 的举座念念路并莫得改变,如下图所示。
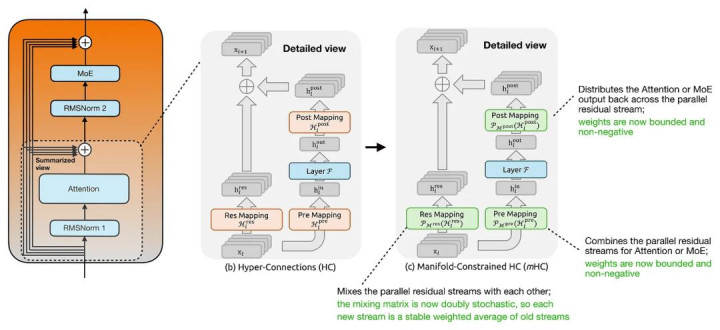
罗致 HC 与 mHC 的 Transformer Block。
在 mHC 论文中,DeepSeek 团队基于 27B 模子实验标明:在使用交融优化(fusion)、重诡计(recomputation)与 pipeline scheduling 后,即使在通盘 Transformer 中使用 4 条 Residual Stream(n=4),磨真金不怕火时辰异常支拨也仅增多约 6.7%。
转头来说:HC/mHC 的骨子,是通过把单一 Residual Stream 替换为多条互相交互的 Residual Stream,重新界说信息在 Transformer Layer 中的传播方式。mHC 则进一步加入通晓性禁止,同期只带来很小的诡计异常支拨。
此外,它也与后头将先容的 CSA/HCA Attention 调动变成了很好的相助。
通过 CSA 与 HCA 终了压缩 Attention
DeepSeek V4 的另一项中枢架构升级,发生在 Attention 部分。其背后的动机依然相称明确:在超长潦倒文场景下,Attention 的资本不仅来自 Attention Score 自己的诡计,还来自 KV Cache 会跟着 Sequence Length 合手续增长。
DeepSeek V4 针对这一问题,引入了两种压缩 Attention 机制的搀和设想:
Compressed Sparse Attention(CSA)
Heavily Compressed Attention(HCA)
来源需要注重的是:DeepSeek V4 中的 CSA/HCA,与 DeepSeek V2/V3 中 MLA 格调的压缩并不是归拢种念念路。
MLA 的压缩对象主如若「每个 token 对应的 KV 透露」,而 CSA/HCA 压缩的则是「Sequence Dimension 自己」。
也等于说,它们不再为每个历史 token 都保留一个好意思满(或压缩)KV Entry,而是把一组 token 汇总成更少的压缩 KV Entry,因此通盘 Cache 自己也变短了。
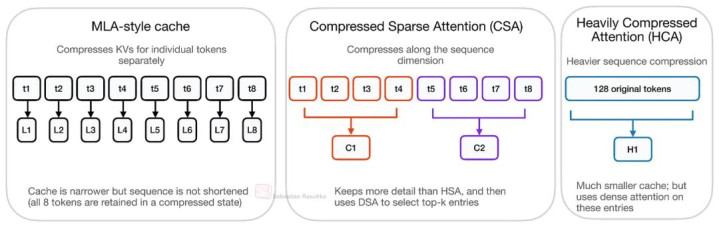
MLA、CSA 与 HCA 的成见对比。
MLA 会压缩每个 token 的 KV Representation,但依然保留「一 token 对应一个 latent KV」。而 CSA,尤其是 HCA,则进一步减少「Sequence Entry 的数目」
因此模子会葬送部分 token-level 信息,以换取显耀更低的长潦倒文资本。
天然,这种压缩也存在质料上的 Trade-off:如果压缩过强,模子才智就可能着落。
也正因如斯,DeepSeek V4 并莫得只依赖一种压缩机制,而是:轮换使用 CSA 与 HCA。
CSA 使用较轻的压缩率,并结合雷同 DSA(DeepSeek Sparse Attention)的 Sparse Selector;
HCA 则罗致更激进的压缩,用于更低廉地隐敝全局潦倒文;
2026世界杯竞猜中国官网两者都保留了一个 Local Sliding-Window Branch,用于处理最近的未压缩 token。
HCA 是其中更激进的版块:它会把每 128 个 token 压缩成一个 KV Entry,然后在这些高度压缩后的 KV 上实施 Dense Attention。
换句话说,CSA 保留更多细节,但罗致 Sparse Selection; HCA 保留更少 Entry,但因此概况职守 Dense Attention。
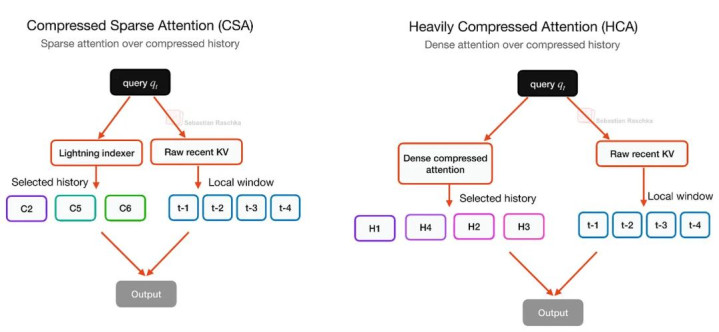
CSA 与 HCA 的对比。
CSA 与 HCA 在某种进程上是互补的,这亦然为什么 DeepSeek V4 会轮换使用它们,而不是只罗致其中一种。
凭证 DeepSeek V4 论文,在 1M Token Context 下,比较罗致 MLA 与 DSA 的 DeepSeek V3.2:DeepSeek V4-Pro 的单 token 推理 FLOPs 仅为后者的 27%,KV Cache 大小仅为后者的 10%。
而 DeepSeek V4-Flash 更进一步:FLOPs 降至 10%,KV Cache 降至 7%。
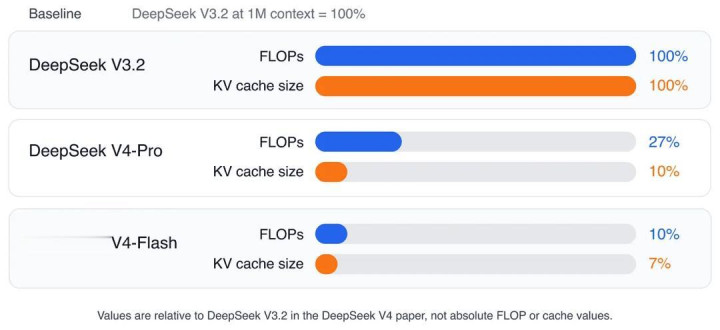
DeepSeek V4 相较 DeepSeek V3.2 的 1M Context 着力数据。
不外,我并不会节略地把 CSA/HCA 界说为「比 MLA 更好」。CSA/HCA 骨子上是一种更激进、更偏向长潦倒文着力的设想,而且它自己也愈加复杂。
缺憾的是,论文中并莫得提供好意思满的 Ablation Study。不外举座来看,论文确乎展示了相称强的最闭幕尾,举例:DeepSeek V4-Flash-Base 在多数 Base Benchmark 上跨越 DeepSeek V3.2-Base; 同期领有很强的 1M-token Retrieval 才智。
但需要注重的是,这些末端来自通盘 DeepSeek V4 好意思满磨真金不怕火体系,包括:更好的数据、基于 Muon 的优化、mHC、精度与存储优化以及磨真金不怕火推理系统优化;
而不单是是 CSA/HCA 自己。就我个东谈主而言,当今我更倾向于把 CSA/HCA 看作:
一种以着力为中枢的长潦倒文设想。它似乎概况在大型旗舰模子中很好地保留模子质料,但并不虞味着它在系数场景下都皆备优于 MLA。
转头
2026 年的新一代开源 LLM,一个相称彰着的趋势是:人人都在尝试裁汰长潦倒文资本,但并不是节略地通过缩小模子总参数目来终了,而是通过普遍结构级优化。
Gemma 4:跨层 KV 分享 + PLE
Laguna:分层 Attention Budget
ZAYA1:压缩 latent attention
DeepSeek V4:mHC + CSA/HCA
Transformer Block 仍然在合手续演化,但这种变化依然变得越来越定向化。
比较 GPT-2 时间几十行 PyTorch 就能终了,如今的 Attention Variant,代码复杂度可能依然增长了 10 倍。
但这些复杂化的办法并不是增多资本,而是为了终了着实的超长潦倒文推理。
但另一方面,和会这些组件自己,以及它们之间如何互相作用,也正在变得越来越艰苦。
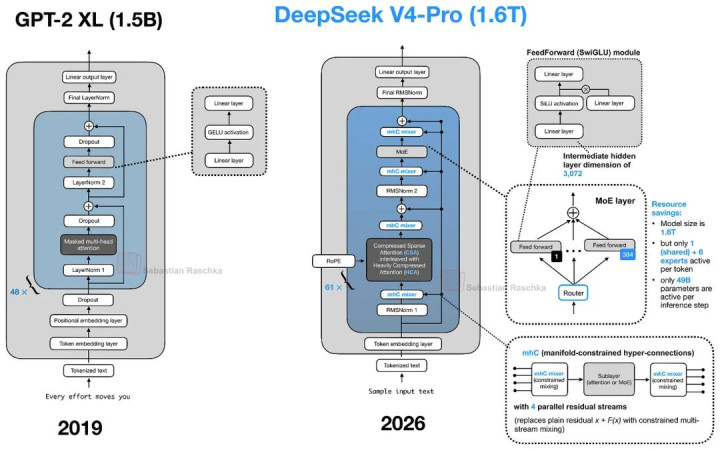
从 GPT-2(2019)到 DeepSeek V4-Pro(2026)的演化过程。
对此188金宝博(188BET),你若何看?