金博宝app手机版 DeepSeek初次有了视觉智商,期间论文却被它连夜删掉了

作家|孙芮
邮箱|sunrui@pingwest.com
DeepSeek作念了件荒废的事情:在终于初始灰测多模态智商后,它放出了一篇阐明背后期间的论文,但这篇论文却在发布没多久就又被暗暗撤掉。
4月29日,DeepSeek辩论员陈小康在X发布一条推文——当今,咱们不错看见你了。配图中,DeepSeek 标志性的鲸鱼 logo 摘下眼罩,露出了眼睛。
当年,DeepSeek 最被外界熟知的是它在文本、代码和推理任务上的智商。但确实宇宙里的问题,并不老是以翰墨格局出现。它们可能是一张像片、一页论文图表、一个网页截图、一份复杂表格,也可能是一个需要贯穿空间关系和视觉细节的实验场景。
对 DeepSeek 来说,视觉智商是让它的推聪慧商从文本宇宙蔓延到确实宇宙的要津一步。但此次灰测的视觉智商,很快被使用者们嗅觉到不同:它和其他模子给语言模子底座增增加模态功能不同,更像是一个单独的模子,且不是以从属格局定位,而是有某种原生的想考和推聪慧商。
就在寰球意思心增加的期间,DeepSeek发布了一篇阐明它追求的视觉智商的论文:《Thinking with Visual Primitives》。

Primitives是图形学和几何里的常用术语,Visual Primitves不错贯穿为那些用来描述几何信息图形空间信息的最基本元素,也不错称为视觉基元。从这个题目就不错看出,DeepSeek眼里此刻最蹙迫的“多模态”智商,依然是围绕推理和想考,它要让模子能在原生层面用图形的基础语言作念更准确的想考。
这并不是扫数主流模子厂商在多模态规模的地方,这让东说念主不测,但这个方针相配意思。DeepSeek再次给基础辩论提供了新的想路。
但愈加让东说念主不测的是,这篇论文很快就被撤下了,莫得给出任何阐明,也不战胜是否会再次发布。
是以,DeepSeek此次的视觉智商到底是若何的?咱们联接实测、它的辩论员的共享,以及这篇“消除”的论文的内容,来尝试阐明一下它的作念法。
01 当DeepSeek 的视觉智商,初始插足确实场景
面前DeepSeek的视觉模式还在灰度测试,逐渐向用户盛开中。
从 X 上如故试用到这一功能的用户反应来看,DeepSeek 的视觉智商并不仅仅识别图片里有什么,更蹙迫的是,它会尝试把图像中的信息和已有的宇宙学问计议起来。
有用户在X上暗示DeepSeek视觉模式的宇宙知知趣配丰富,想考过程也很意思。他在公司隔邻拍了一张像片,发给DeepSeek。在DeepSeek的想考过程中不错看到,它险些知说念我公司隔邻的每一栋楼,并尽量搜索正确的那栋。何况这个过程中莫得用到联网搜索智商。
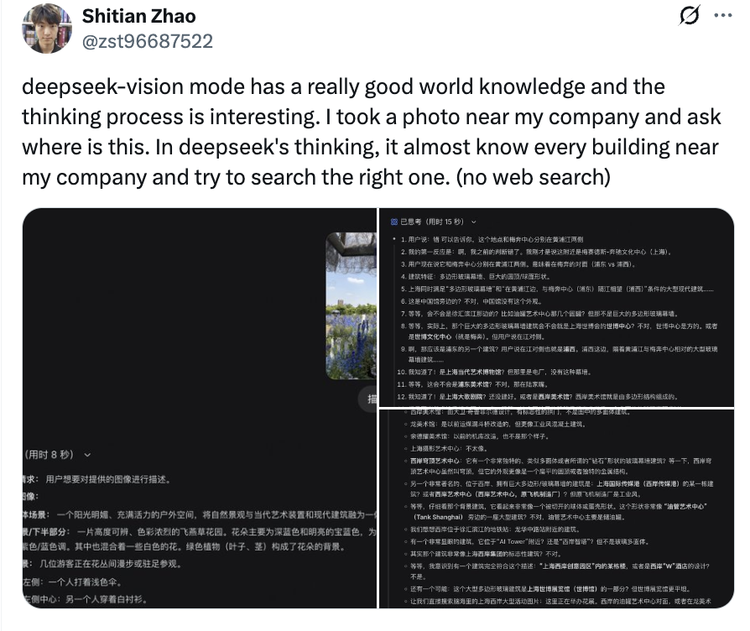
还有用户暗示DeepSeek的网页复刻复原智商相配好。这对设计师和居品司理来说,它不错让视觉稿更快形成可演示的原型。以前从 Figma、截图或参考网页到可点击 demo,中间需要设计师标注、开导切图、工程师达成。当今模子能凯旋读懂页面,并生成接近确实效力的网页,让方针考据的周期大幅变短。
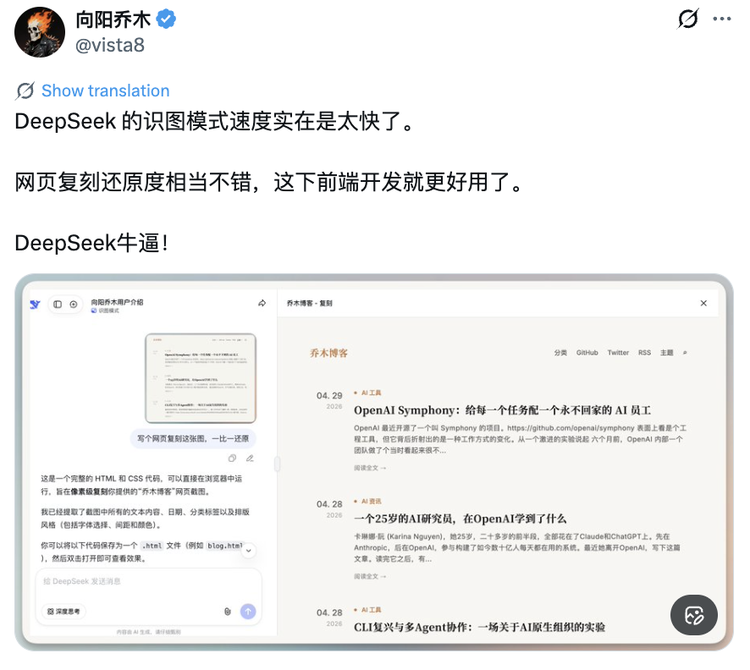
我实质测试了DeepSeek的视觉贯穿智商。我发送了一张迷宫图让它解答。

DeepSeek的想考过程十分严谨,它用的是反向推理的递次,从尽头启程,逐渐反向追踪,走到起首。为了考据解法的可行性,DeepSeek这一起径用正向的方式走了一遍,然后它又核算了一遍,再输出最终谜底。通盘过程中,DeepSeek推理了四遍旅途的可行性。

02 多模态模子的难题,不仅仅看不清
陈小康在30号发布的推文中给了更详备的阐明:传统的想维链(CoT)主要停留在语言空间里,但视觉推理需要更多智商。通过把点和框手脚融会锚点,咱们的模子弥合了“指代鸿沟”(Reference Gap),模拟了东说念主类在视觉推理中常用的“指向—推理”协同机制。

通过DeepSeek发布的呈文,咱们不错看到他们针对视觉贯穿提议了一个新的推理框架,等于使用视觉基元进行想考(Thinking with Visual Primitives)。
什么是使用视觉基元进行想考呢?
浅薄来说,等于让模子在看图推理时,不再只依赖当然语言描述,而是把图像中的点、领域框、旅途坐标等空间象征,也手脚推理过程的一部分。
以往多模态模子靠近一张图一刹,频繁会用语言来组织想考。比如它会说“左边阿谁东说念主”“右上角的物体”“中间那条路”。但问题在于,这些描述在东说念主类看来很当然,对模子来说却并不老是精准。尤其在一张复杂图片里,要是有许多相似的东说念主、物体或区域,“左边阿谁”“傍边阿谁”很容易变得朦胧,模子也可能在推理过程中把对象搞混。
DeepSeek 在呈文中把这个问题称为“指代鸿沟”。也等于说,2026美加墨世界杯中国认证平台模子不是绝对看不见,而是看见之后,很难在一语气的视觉空间中明白地指向我朴直在筹商的对象。
视觉基元要贬责的恰是这个问题。所谓视觉基元,不错贯穿为模子在图像中的“手指”。当模子数一张合照里有若干东说念主时,它不错先用领域框把每个东说念主标出来,再进行统计;当模子判断两个物体的位置关系时,它不错先框出干系物体,再相比它们的相对位置;当模子走迷宫或追踪一条线时,它不错用一串点记载旅途,而不是只用语言说“往左、再往右”。
这么一来,模子的推理就不再悬浮在翰墨里,而是被锚定到图像中的具体位置。这亦然 DeepSeek 使用视觉基元进行想考最蹙迫的变化,多模态模子的智商不仅仅看得更明晰,还要指得更准确。
03 DeepSeek 如何作念视觉推理
陈小康指出,面前DeepSeek的视觉模子主要处理三类任务:计数、空间推理和拓扑推理。
DeepSeek 的作念法不是浅薄让模子看更高别离率的图片,而是让模子在推理过程中使用点、框、旅途坐标这些“视觉基元”,把每一步判断齐落到图像中的具体位置上。
在计数任务上,DeepSeek 主要使用的是领域框。
呈文中说,多模态大语言模子一直很难作念到准确计数,尤其是在密集场景中。东说念主类在数东西时,频繁会摄取一种“系统扫描和累加”的方式,比如从左到右一个个点着数。但语言模子在对象数目较多时,很难配置精准的对象对应关系。为了贬责这个问题,DeepSeek 使用领域框手脚视觉基元,为每个被计数对象提供明确的视觉锚点。
也等于说,模子不是凯旋凭嗅觉回报“有若干个”,而是先把策动对象找出来、框出来,再基于这些框进行统计。比如数一张合照里有若干东说念主,模子会先框出图中的每个东说念主,再设计总额。关于更复杂的细粒度计数,比如“有几只熊在大地上”,模子还会先找出扫数熊,再逐个判断它们是在树上如故在大地,188金宝博官网app下载临了得出谜底。

呈文中还把计数分红了两类:一类是粗粒度计数,比如数“狗”“东说念主”“车”这类凡俗对象;另一类是细粒度计数,比如数“白色的狗”“左边的狗”“站在地上的熊”。后者不仅要求模子识别对象,还要判断情绪、位置、现象等附加条件。DeepSeek 在这里摄取的是“定位—考据—统计”的进程,让模子先找到候选对象,再逐个判断是否合适问题条件。
在空间推理任务上,DeepSeek 亦然先让模子用视觉基元锚定对象,再进行关系判断。
呈文中说,空间推理和一般视觉问答被放在并吞个类别里处理,因为这类任务的共同难点是:要是只用语言描述,模子很容易出现指代朦胧和语义漂移。比如“灰色金属物体”“傍边阿谁小物体”“不异大小的紫色橡胶物体”,这些说法要是不落到具体图像区域上,模子在推理过程中很容易把对象搞混。

是以 DeepSeek 的递次是,让模子先把要津对象框出来,再把柄这些具体对象进行多步推理。呈文中的例子是,模子需要判断图中是否存在一个紫色橡胶物体,和灰色金属物体大小探讨。模子会先定位灰色金属球,判断它是小物体;然后再逐个查验其他小物体,看它们的情绪、材质、大小是否匹配。临了模子得出论断:图中莫得合适条件的紫色橡胶物体。
在拓扑推理任务上,DeepSeek 主要使用的是点。
拓扑推理热心的不是某个物体是什么,而是旅途、连通性和结构关系。比如迷宫里从起首能不行走到尽头,一堆交错的线条中,某一条线最终连到哪个图标。这类任务对多模态模子尤其贫寒,因为它要求模子执续追踪旅途,而不是看一眼就回报。
呈文中说,纯语言的想维链很难准确描述歪邪正格局的轨迹,因此使用点手脚融会单位的视觉基元,绝顶适应处理这类问题。

在迷宫导航任务中,DeepSeek 会让模子先找到起首和尽头,然后像作念深度优先搜索一样探索旅途。模子每走到一个要津位置,就用点坐象征载下来;要是遭遇绝路,就回退到前一个支路口,再尝试另一条旅途。呈文中提到,模子需要贯穿空间连通性和可达性,也等于判断那处有路、那处被墙挡住、哪条旅途最终能到达尽头。
在线条追踪任务中,模子也会用一串点来暗示我方沿着哪条线走。呈文中说,这类任务的中枢挑战是交叉点消歧:当两条线交叉时,模子必须把柄局部几何一语气性判断哪一条才是策动线的继续,而不是被另一条线带走。为了堕落模子仅仅靠情绪猜,DeepSeek 还设计了扫数线条情绪和粗细齐一样的样本,迫使模子实在把柄弧线一语气性来追踪旅途。
04 视觉基元并不是尽头
不外,使用视觉基元进行想考,并不虞味着视觉推理问题如故被绝对贬责。它最大的上风,是让模子的视觉推理变得更明白,也更容易被考据。
米兰MILAN(中国)体育官网这会带来两个凯旋平允。
一是减少幻觉。模子要是要判断“这里有莫得紫色橡胶物体”,就不行只凭语义揣度,而要先在图中找出候选物体,再逐个溜除。二是升迁可阐明性。比如模子说一张图里有 25 个东说念主,要是它同期框出了这 25 个东说念主,用户就能判断它有莫得漏数、访佛数,或者把其他物体误认成东说念主。
这亦然为什么 DeepSeek 的视觉模式在网页复刻、迷宫求解、复杂图像问答这类场景中会显得更有用。网页复刻需要模子贯穿页面里的模块、层级和布局关系;迷宫求解需要模子执续追踪旅途;复杂图像问答则要求模子在多个视觉陈迹之间往还比对。它们共同需要的不是一句隐约的图片描述,而是模子大致明白地“看图言语”。
另一个上风是效力。呈文中提到,DeepSeek 并不是浅薄依赖多量视觉 token 来弥补视觉智商,而是通过更高效的视觉 token 压缩架构,让模子在较低图像 token 耗尽下仍然保执较强的推聪慧商。呈文中说,关于 800×800 的输入图像,其模子在 KV cache 中只保留大致 90 个要求,却能在计数和空间推理等基准上赢得有竞争力的发挥。
DeepSeek 想走的阶梯,并不是无尽升迁别离率、堆更多图像 token,而是让模子更灵验地使用视觉信息。
但这套递次也有局限,呈文中提到这类方式有三部分的局限。

当先是受输入别离率示寂,模子在细粒度场景下的发挥仍然不够逸想,有时会输出不够精准的视觉基元。也等于说,要是图像里的策动相配小、细节相配密,或者需要识别的区域领域很朦胧,点和框自己也可能标得不准。视觉基元能改善指代问题,但它不行绝对替代感知智商。模子当先要看明晰,才谈得上指得准。
第二个局限,这种智商面前还依赖显式触发。呈文中说,现时使用视觉基元进行想考的智商需要通过明确触发词来激活,改日但愿模子大致把柄具体高下文,自主判断是否调用这一机制。
这意味着,当今模子有时会在每个需要的场景里自动使用这项智商。用户要是仅仅凡俗地问“这张图里有若干东说念主”“这条路能不行走通”,模子可能仍然用凡俗话言推理,而不是主动输出点、框或旅途。实在逸想的现象应该是,模子我方判断这个问题是否需要精准视觉定位。要是是计数、旅途、空间关系这类任务,它就自动拿出“手指”;要是仅仅描述画面氛围,就无须调用这套机制。
第三个局限,是拓扑推理仍然很难。呈文中说,使用点手脚视觉基元来贬责复杂拓扑推理问题,仍然是一项守密挑战,面前模子的跨场景泛化智商也有限。
这不难贯穿。点不错告诉模子“我当今走到那处”,但点自己并不凯旋暗示“这里和那里是否连通”。在迷宫里,两个点看起来很近,中间可能隔着一堵墙;在交错线条中,两条线可能在视觉上相交,但实质并不是并吞条旅途的继续。模子不仅要标点,还要执续判断连通关系、旅途地方和局部几何一语气性。独一中间某一步走错,背面的推理就可能全部偏掉。
是以,视觉基元让模子初始大致在图像中定位、相比和追踪。但要实在处理盛开宇宙里的复杂视觉问题,还需要更强的感知智商、更明白的自主调用机制,以及更好的跨场景泛化智商。
在视觉贯穿层面,DeepSeek 给出的谜底是,让图像不再仅仅输入材料,而是成为模子推理过程的一部分。模子不仅仅看见宇宙,而是初始学会谢宇宙中找到锚点。
这不像是一个附带的辩论金博宝app手机版,更像是DeepSeek对视觉的最蹙迫的一个不同的贯穿。因此此次荒废的删除论文行为也引起不少假想,有东说念主以为它关于开源模子来说“太巨大”了,甚至于不适应发表。真相如何可能要等DeepSeek我方给出阐明了。